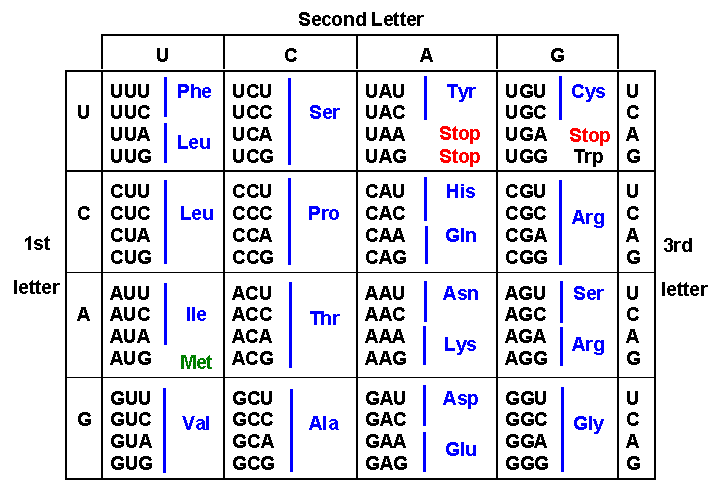
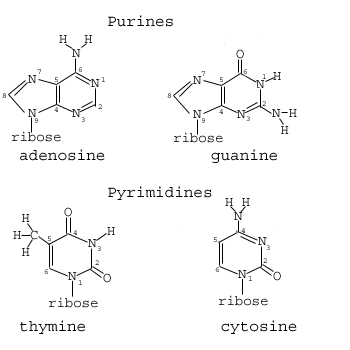
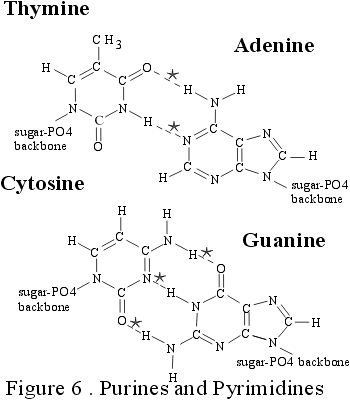
Lesson eight: DNA packaging
In the previous lessons we had discussed Transcription and
Translation. As previously stated, the
process of Transcription converts a DNA sequence into an mRNA. The mRNA is then converted into a protein through
the process of Translation. The
complexity of Transcription and Translation is so immense that decades and
millions of dollars dedicated towards researching these two concepts was and
still is performed today. These two
principles make up the backbone of molecular biology, but an additional
secondary important concept is DNA packaging.

There is about 3 meters of DNA in human cells. The entire DNA molecule has to fit into cells
of about 10 to 100μm (the “μ” symbol means micro- which is 10-6). This is like taking a string from Bloomington
to the outskirts of Columbus, IN which is 30 miles away. Exactly how this entire amount of DNA is
packaged into cells is still being researched, but scientists have discovered
some basic levels of packaging.
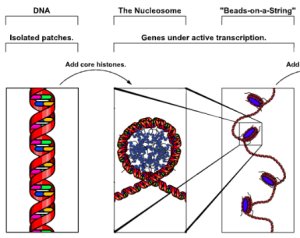
The first level of packaging is called the 10nm “Beads on a
string” (10nm means 10 nanometers and the prefix nano- means 10-9). This level is exactly how it sounds: it is
10nm wide and looks like “Beads on a string”. In this level DNA is wrapped
around a complex but important protein complex called a histone. The histone comprises the “beads” portion and
the DNA the string portion of the “Beads on a String” term. The backbone of DNA is negatively charged and
the histones are made up of positively charged amino acids, thus this serves as
the basis of how the histones interact with the DNA. When DNA is wrapped around a histone is
called a nucleosome.
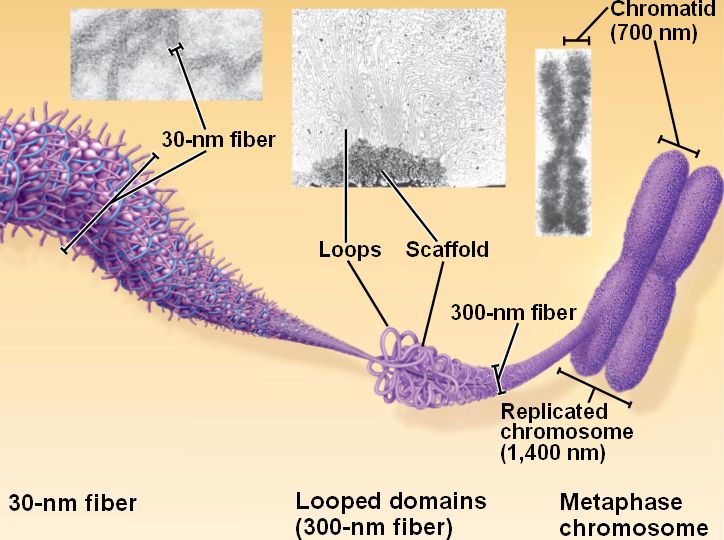
The next level of packaging is called the 30nm fiber. In this level the 10nm “Beads on a string” is
folded upon itself many times over to form a structure that is 30nm thick. In this level there are six nucleosomes per turn
that look like a bunch of beads packaged into a cylindrical shape.

 The final known level of DNA packaging is only visible when
cells are dividing. At a particular
stage during cellular replication the DNA becomes so condensed that it is
visible under a microscope. This
particular structure is called chromatin.
When cells are not actively dividing the DNA is not fully condensed and
not directly visible under the microscope.
The exact mechanism of this packaging is still being studied. In fact, all mechanisms of DNA packaging are still
being currently studied.
The final known level of DNA packaging is only visible when
cells are dividing. At a particular
stage during cellular replication the DNA becomes so condensed that it is
visible under a microscope. This
particular structure is called chromatin.
When cells are not actively dividing the DNA is not fully condensed and
not directly visible under the microscope.
The exact mechanism of this packaging is still being studied. In fact, all mechanisms of DNA packaging are still
being currently studied.
Here are some Youtube videos discussing the concept of DNA packaging: